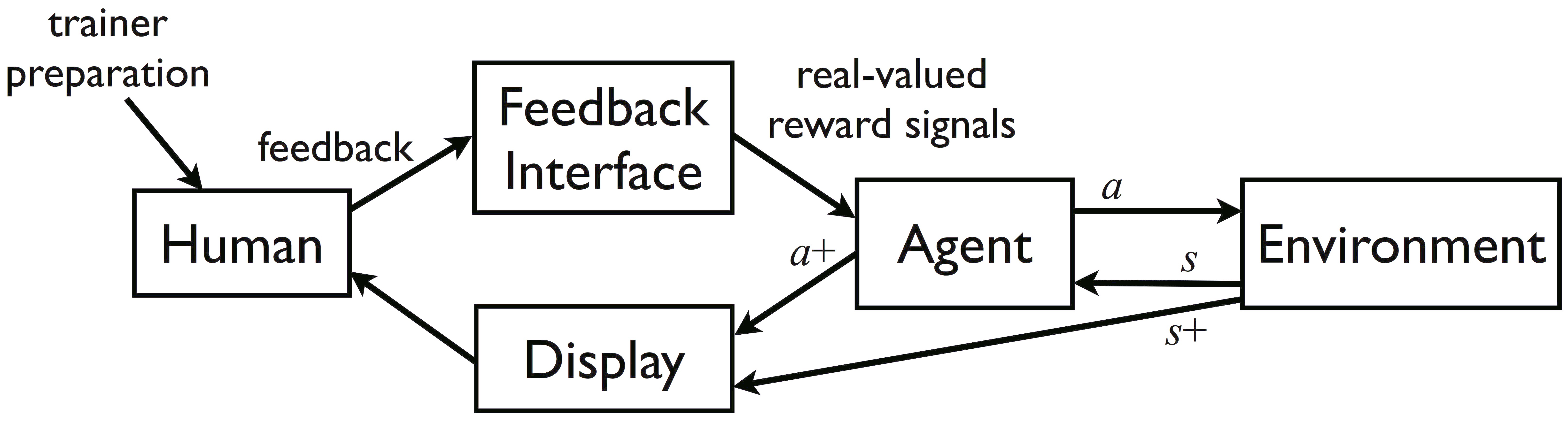
The Interactive Shaping Problem of learning from human-generated reward:
Within a sequential decision-making task, an agent receives a sequence of state descriptions (s1, s2, … where si ∈ S) and action opportunities (choosing ai ∈ A at each si). From a human trainer who observes the agent and understands a predefined performance metric, the agent also receives occasional positive and negative scalar reward signals (h1, h2, …) that are positively correlated with the trainer’s assessment of recent state-action pairs. How can an agent learn the best possible task policy (π : S → A), as measured by the performance metric, given the information contained in the input?
The definition above is a condensed version of the full current definition, which can be found in Chapter 2 of my dissertation. The TAMER framework is our successful approach to the Interactive Shaping Problem. In Chapter 6 of my dissertation, our investigation of reward discounting lays out a path towards approaches that may be even more effective than TAMER.
It’s worth noting that though our broad goal is to create agents that can be trained to perform any task, we often restrict the Interactive Shaping Problem to tasks with predefined performance metrics to allow evaluation of the quality of shaping algorithms.