This page needs updating. Most recent work can be found here.
Some recent papers:
- 2023 – In a AAAI paper led by Serena Booth, we examine how RL experts tend to overfit reward functions via the dominant practice of trial-and-error reward design.
- 2022 – In RLHF research, we propose an alternative to the Cristiano et al. model of how humans give preferences over trajectory segments. It has better theoretical properties and we observe improved performance with human preferences. And it makes more intuitive sense as a model of human preference, considering important characteristics of a trajectory segment like its end-state value and how suboptimal its actions are.
Finding Flaws in Reward Design: A Case Study in Autonomous Driving
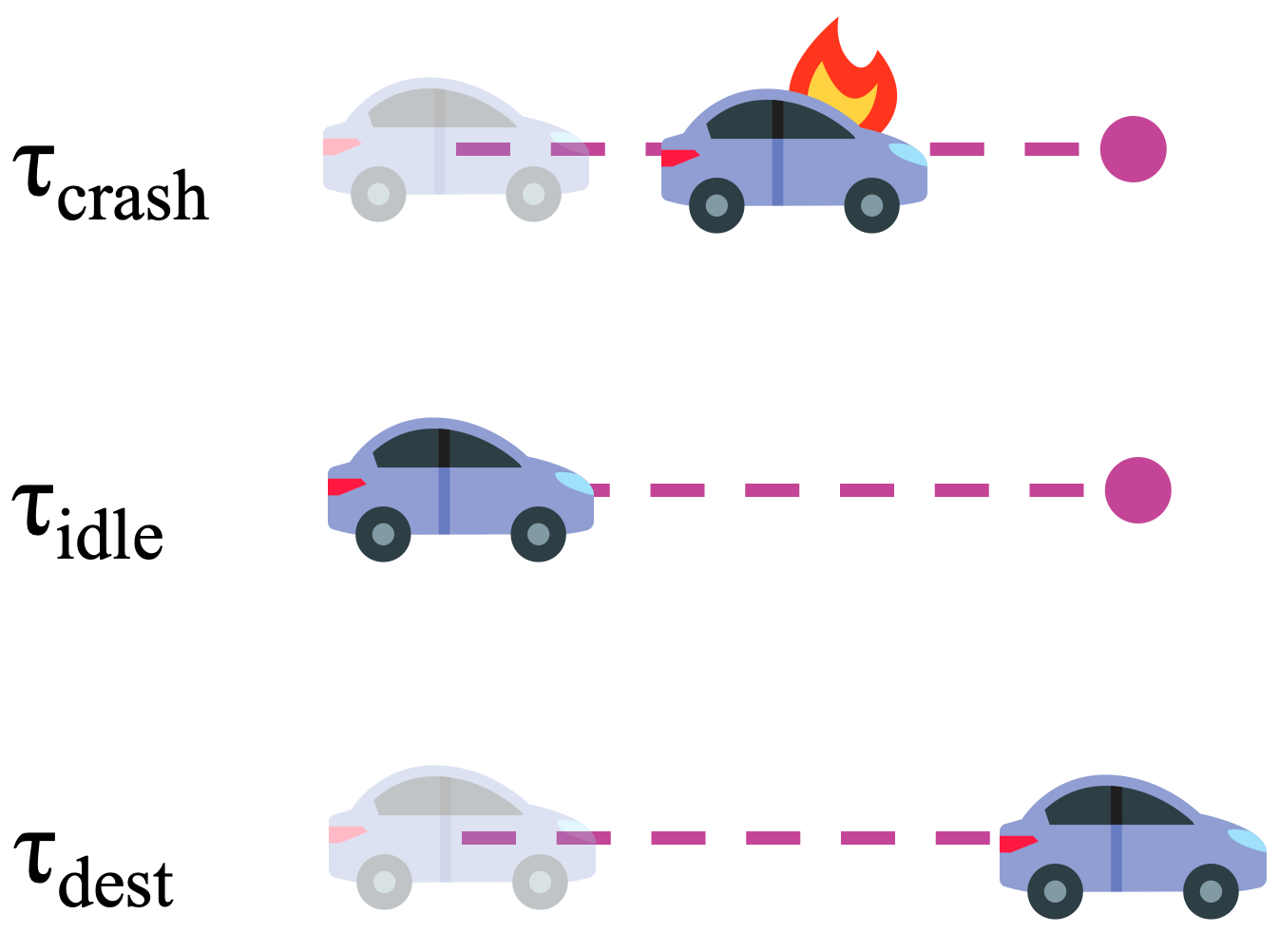 Reinforcement learning for autonomous driving holds promise to optimize driving policies from the coming fire hose of driving data. But as an optimization algorithm, RL is limited by the reward function it’s optimizing against. To aid reward design, we present 8 sanity checks for a reward function in any domain. We apply these to published reward functions for autonomous driving and find an alarming pattern of frequent failures.
Reinforcement learning for autonomous driving holds promise to optimize driving policies from the coming fire hose of driving data. But as an optimization algorithm, RL is limited by the reward function it’s optimizing against. To aid reward design, we present 8 sanity checks for a reward function in any domain. We apply these to published reward functions for autonomous driving and find an alarming pattern of frequent failures.
[Caption for image to left] 3 canonical trajectories used for evaluating reward functions. These trajectories can more generally can be thought of, from top to bottom, as a failed gamble, a safe default, and a successful gamble.
AIJ 2023
Learning from Implicit Human Feedback, 2019-2021
 Reactions such as gestures, facial expressions, and vocalizations are an abundant, naturally occurring channel of information that humans provide during interactions. This project seeks a rigorous understanding of how a robot or other agent could leverage an understanding of such implicit human feedback to improve its task performance at no cost to the human. We introduce the EMPATHIC framework, which involves learning a reaction mapping from the human to task statistics such as reward.
Reactions such as gestures, facial expressions, and vocalizations are an abundant, naturally occurring channel of information that humans provide during interactions. This project seeks a rigorous understanding of how a robot or other agent could leverage an understanding of such implicit human feedback to improve its task performance at no cost to the human. We introduce the EMPATHIC framework, which involves learning a reaction mapping from the human to task statistics such as reward.
CoRL 2020
Learning Social Interaction from the Wizard, 2012-2014
 To program social robotic behavior, we developed a new technique: Learning from the Wizard (LfW). Here, a robot employs a form of machine learning called learning from demonstration to derive a model of a hidden puppeteer’s control during previous sessions of social interaction. (Interaction with secretly human-controlled interfaces is referred to as Wizard-of-Oz interaction.) With this model, the robot can autonomously emulate its former puppeteer, removing the need for a human operator. We developed and evaluated this technique within the task domain of acting as a robot learning companion, where young children played on an educational app with the robot. The autonomous robot performed as well as a human-controlled robot on most metrics. Curiously, when the metrics differed considerably, they appeared to favor the autonomous robot, which was judged as a more desirable play companion, more like a peer, and less like a teacher.
To program social robotic behavior, we developed a new technique: Learning from the Wizard (LfW). Here, a robot employs a form of machine learning called learning from demonstration to derive a model of a hidden puppeteer’s control during previous sessions of social interaction. (Interaction with secretly human-controlled interfaces is referred to as Wizard-of-Oz interaction.) With this model, the robot can autonomously emulate its former puppeteer, removing the need for a human operator. We developed and evaluated this technique within the task domain of acting as a robot learning companion, where young children played on an educational app with the robot. The autonomous robot performed as well as a human-controlled robot on most metrics. Curiously, when the metrics differed considerably, they appeared to favor the autonomous robot, which was judged as a more desirable play companion, more like a peer, and less like a teacher.
2014 AAAI MLIS workshop, AAMAS 2016
Learning from Human Feedback, 2007-2015
 Much of my research has focused on algorithms that facilitate teaching by signals of approval and disapproval from a live human trainer. Operationalizing these signals as numeric reward in a reinforcement learning framework, we ask: Given the reward that technically unskilled users actually provide, how should a robot learn from these signals to behave as desired by the trainer? Relevant publications: my dissertation and those in sub-projects below
Much of my research has focused on algorithms that facilitate teaching by signals of approval and disapproval from a live human trainer. Operationalizing these signals as numeric reward in a reinforcement learning framework, we ask: Given the reward that technically unskilled users actually provide, how should a robot learn from these signals to behave as desired by the trainer? Relevant publications: my dissertation and those in sub-projects below
Sub-projects on human-generated reward:
TAMER – The TAMER framework is our myopic, model-based approach to learning only from human reward (described further here; videos of training here). Relevant publications: ICDL 2008, K-CAP 2009, HRI Late-breaking Reports 2012, ICSR 2013
TAMER+RL – TAMER+RL incorporates TAMER into various stratgies for learning from both human-generated reward and hard-coded reward from a Markov Decision Process (described further here). Relevant publications: AAMAS 2010, AAMAS 2012
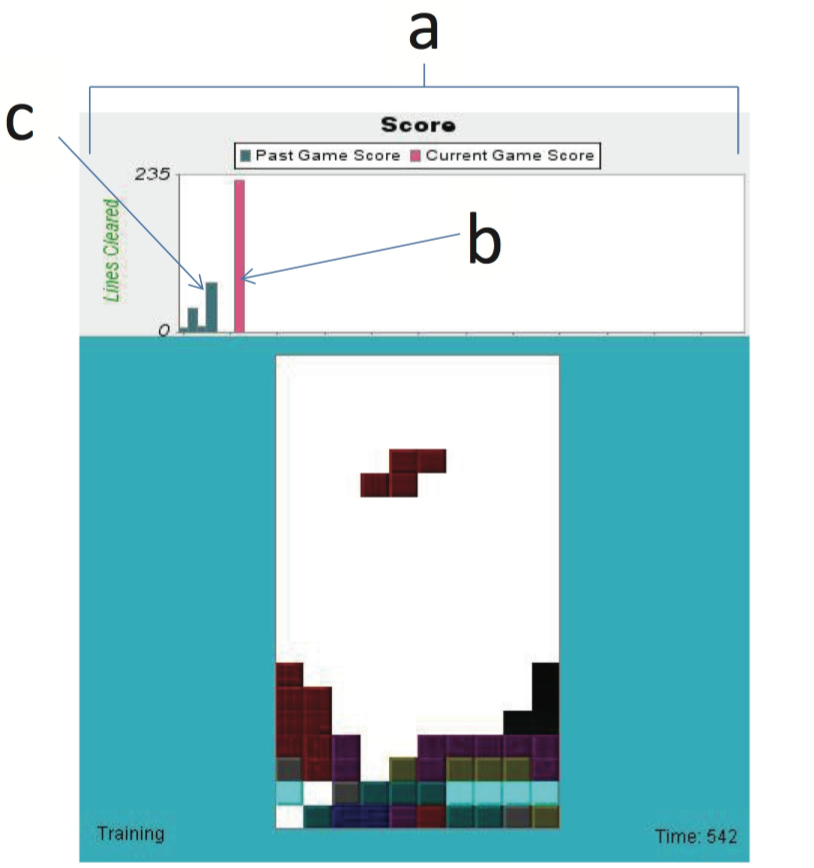 Directly influencing the trainer – Using TAMER agents, we studied how humans trainers respond to changes in their perception of the agent and to certain changes in the agent’s behavior. One contribution of this work is a demonstration that students can induce human teachers to give more frequent feedback by deliberately lowering the quality of their behavior. In other research, we examined how changes to the training interface affected trainers. When the agent displays summaries of its own past performance to the trainer, we found that trainers gave more feedback and trained agents to higher performance levels. However, when the agent instead displays a measurement about its confidence in its own behavior, the trainer gives more feedback but creates worse performance than without an informative interface. Relevant publications: IJSR 2012, AAMAS 2013
Directly influencing the trainer – Using TAMER agents, we studied how humans trainers respond to changes in their perception of the agent and to certain changes in the agent’s behavior. One contribution of this work is a demonstration that students can induce human teachers to give more frequent feedback by deliberately lowering the quality of their behavior. In other research, we examined how changes to the training interface affected trainers. When the agent displays summaries of its own past performance to the trainer, we found that trainers gave more feedback and trained agents to higher performance levels. However, when the agent instead displays a measurement about its confidence in its own behavior, the trainer gives more feedback but creates worse performance than without an informative interface. Relevant publications: IJSR 2012, AAMAS 2013
Aligning Learning Objectives and Task Performance in Reinforcement Learning from Human Reward – In this line of research, we examined the impact of various algorithmic assumptions (e.g., the temporal discount rate and whether the agent experiences separate episodes of learning) on the agent’s performance on the task (described further here). Relevant publications: Ro-Man 2012, IUI 2013
Inferring Trust for HRI, 2012-2013
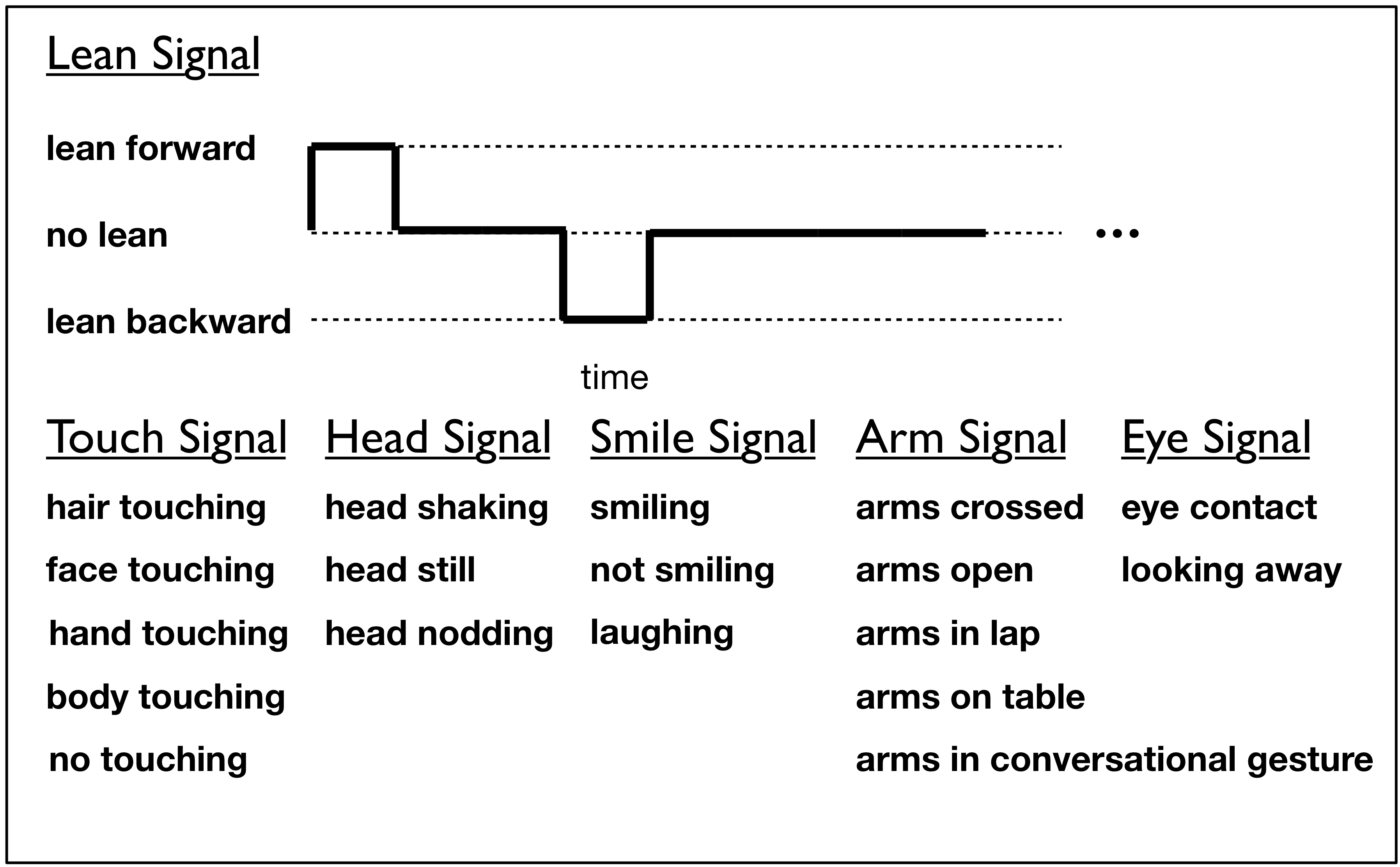
Nonverbal behaviors such as gaze patterns, body language, and facial expressions have been explored as “honest” or “leaky” signals that are often unconsciously given and received. Using supervised learning, we created a computational model to assess interpersonal trust in social interactions, discriminating by the trust-related nonverbal cues expressed during this social interaction. Feature generation and extraction are informed by previous psychological studies on nonverbal behavior and trust. In predicting trust-based behavior in an economic exchange game, the trust classifier significantly outperforms human judgment and various baseline models. Through this work on learning evaluative models of human trust, we hope to enable a robot to judge how trusted it is by its human collaborators. With this feedback signal, robots can learn how to build trust, which has been shown to improve communication and may thus be critical for human-robot collaboration. Frontiers in Psychology, 2013.
Interactive Museum of Reinforcement Learning, 2013
The Interactive Museum of RL is a series of Java applets that show various combinations of reinforcement learning algorithms and task environments. It is meant as a place for those who are new to reinforcement learning to obtain an intuitive understanding of the field. Agents and environments are connected and visualized by RL Applet (see below). More agents and environments are needed. Please contact me if you have some of either to add.
RL Applet, 2012
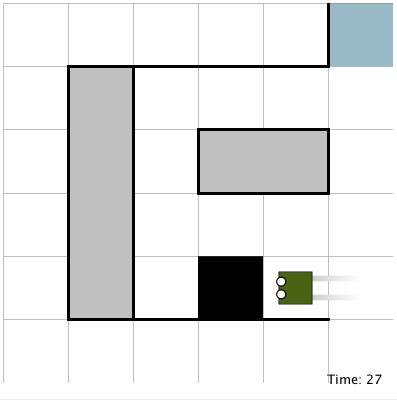 Building upon the Java libraries for RL-Glue, I created an applet that can display real-time reinforcement learning. This applet runs in the web browser of nearly any user. Its intended functions include improving public awareness of reinforcement learning, aiding the teaching/understanding of reinforcement learning algorithms, and inspiring students to study reinforcement learning. Further, RL Applet can easily be adapted to allow human interaction with learning agents. Any Java-based, RL-Glue-compatible agent can be used, and environments must be Java-based and compatible with RL-Library‘s RL Viz application. (More info and source download here.)
Building upon the Java libraries for RL-Glue, I created an applet that can display real-time reinforcement learning. This applet runs in the web browser of nearly any user. Its intended functions include improving public awareness of reinforcement learning, aiding the teaching/understanding of reinforcement learning algorithms, and inspiring students to study reinforcement learning. Further, RL Applet can easily be adapted to allow human interaction with learning agents. Any Java-based, RL-Glue-compatible agent can be used, and environments must be Java-based and compatible with RL-Library‘s RL Viz application. (More info and source download here.)
Belief-Directed Exploration in Humans, 2010-12
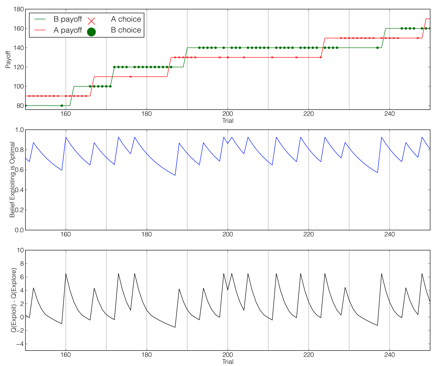 To study the trade-off in humans between exploiting current knowledge of best behavior or exploring to learn more about behavioral outcomes, we calculated a model of optimal behavior on an experimental task that is partially observable, formulating the task as a POMDP. Fitting human task behavior with this model and less optimal variants, we found that human behavior appears reflective—considering past experience and unobservable task dynamics—but suboptimally lacks a precise assessment of the informational value of exploration. Relevant publication: Frontiers in Psychology 2012
To study the trade-off in humans between exploiting current knowledge of best behavior or exploring to learn more about behavioral outcomes, we calculated a model of optimal behavior on an experimental task that is partially observable, formulating the task as a POMDP. Fitting human task behavior with this model and less optimal variants, we found that human behavior appears reflective—considering past experience and unobservable task dynamics—but suboptimally lacks a precise assessment of the informational value of exploration. Relevant publication: Frontiers in Psychology 2012
Improving Fraud Detection through Relational Modeling, 2010
Working with Appleʼs Data Mining Group in a 2010 internship, I improved their established fraud-detection model by constructing relational features that exploit the interdependence of online orders. On historical data, these improvements catch an additional $3.5 million of attempted fraud annually, almost half of what was previously missed.
Automatic Diagnosis of Electrical System Failures, 2008
At NASA Ames, I worked with Dr. Ole Mengshoel on automatic diagnosis of electrical system failures, modeling the system with large dynamic Bayesian Networks. Before I departed, we took steps toward diagnosing and reconfiguring the system to adapt to failures. Relevant publication: IJCAI 2009 Workshop on …
 Home-assistant robots, 2006-07
Home-assistant robots, 2006-07
On a robot built from a Segway RMP base, we designed simple behaviors that build towards the complex capabilities required by a home-assistant robot. Especially adept at recognizing people, our robot earned 2nd place among 11 excellent teams in the 2007 Robocup@Home competition. Full website. Relevant publications: Robocup Symposium 2008, JoPha 2008
Opponent Modeling in the Robocup Coach Competition, 2005-2006
In the Robocup Simulated Coach League, participants’ algorithms must infer what patterns are being displayed by a simulated soccer team. For example, a pattern could be that Player 1 dribbles to the goal area and then passes to Player 2, who then shoots on the goal. For my first research project, I developed an opponent modeling algorithm that competed in the 2005 Robocup Simulated Coach League and emerged as world champion. The following year we received 2nd place. Relevant publication: AAAI 2006